Your file upload works perfectly in development.
You test it locally. Maybe even with a few users. Everything feels smooth and reliable.
Then real users arrive.
Suddenly, uploads fail halfway. Large files time out. Servers slow down. And users start abandoning the process.
This is where most teams hit a harsh reality:
What works in development rarely works at scale.
A scalable file upload API isn’t just about handling more users. It’s about surviving real-world conditions like unstable networks, large files, global traffic, and unpredictable behavior.
In this guide, you’ll learn:
Why file upload systems fail at scale
The hidden architectural issues behind those failures
How to design a reliable, scalable upload system that actually works in production
Key Takeaways
File upload failures at scale are caused by concurrency, large files, and unstable networks
Single-request uploads are fragile and unreliable in production environments
Chunking, retries, and parallel uploads are essential for scalability
Backend-heavy architectures create performance bottlenecks
Managed solutions simplify complexity and improve reliability
Why File Upload APIs Work in Testing but Fail in Production
File upload APIs often feel reliable during testing because everything happens under ideal conditions such as fast networks, small files, and minimal traffic. But once real users come in with larger files, unstable connections, and simultaneous uploads, those same systems start to break in ways you didn’t expect.
The “It Works on My Machine” Problem
In development, everything feels predictable. You’re working with a fast, stable internet connection, testing with small files, and usually running just one or two uploads at a time. Under these conditions, your file upload API performs exactly as expected. It’s smooth, fast, and reliable.
But production is a completely different story.
Real users don’t behave like test environments. They upload large files, sometimes 100MB or more. Multiple users are uploading at the same time. And not everyone has a stable connection; some are on slow WiFi, others on mobile data with frequent interruptions.
This mismatch between controlled testing and real-world usage is where things start to fall apart. What seemed like a solid system suddenly struggles under pressure, revealing weaknesses that were never visible during development.
What “Scale” Really Means
When people talk about scale, they often think it simply means more users or more traffic. But in file upload systems, scale is much more complex than that.
It’s a mix of several factors happening at the same time. You might have hundreds of users uploading files simultaneously, each with different file sizes; some small, some extremely large. On top of that, those users are spread across different locations, all connecting through networks that vary in speed and reliability.
All of these variables combine to create pressure on your system in ways that aren’t obvious during testing. A setup that works perfectly for 10 uploads can start to struggle or even fail completely when it has to handle 1,000 uploads under real-world conditions.
7 Reasons Your File Upload API Fails at Scale
When upload systems start failing in production, it’s rarely due to a single issue. More often, it’s a combination of architectural decisions that work fine in small-scale environments but break under real-world pressure. Let’s walk through the most common reasons this happens.
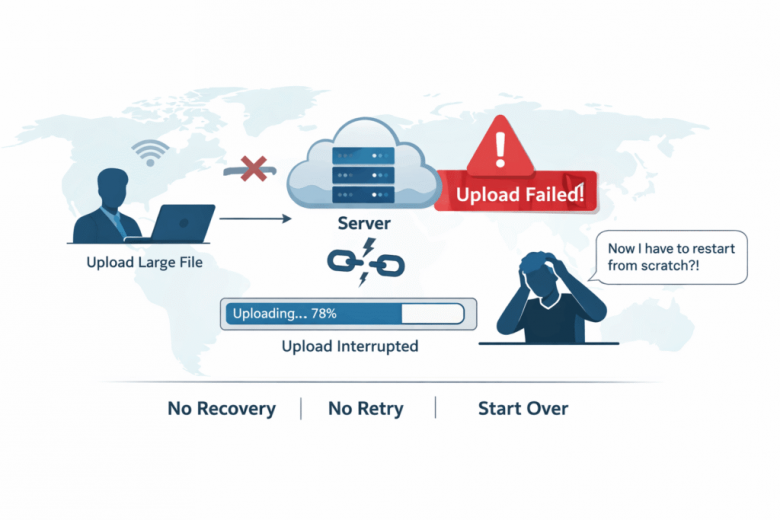
1. Single Request Upload Architecture
One of the most common mistakes is trying to upload an entire file in a single request. It seems simple and works well during testing, but it becomes extremely fragile at scale.
In real-world conditions, even a small interruption like a brief network drop or a timeout can cause the entire upload to fail. And when that happens, the user has to start over from the beginning. There’s no recovery mechanism, no retry logic, and no way to resume progress. It’s all or nothing.
2. No Chunking or Resumable Uploads
Without chunking, your upload system has no flexibility. Files are treated as one large unit, which means any failure resets the entire process.
This leads to a few major problems:
Users have to restart uploads from zero after any interruption
Frustration increases, especially with large files
Completion rates drop significantly
At scale, this approach simply doesn’t hold up. Resumable uploads aren’t a “nice-to-have” feature; they’re a necessity for maintaining reliability and user trust.
3. Backend Bottlenecks
Many systems route file uploads through their backend servers. While this might seem like a straightforward approach, it quickly becomes a bottleneck as usage grows.
Your backend ends up doing everything:
Handling file transfers
Processing uploads
Storing data
As traffic increases, this creates heavy pressure on your server’s CPU and memory. Performance starts to degrade, response times increase, and in some cases, the system can even crash under load.
4. Poor Network Failure Handling
In development, networks are stable. In production, they’re not.
Users experience:
Sudden connection drops
Fluctuating bandwidth
Packet loss
If your system isn’t designed to handle these issues, uploads will fail unpredictably. Without proper retry logic or recovery mechanisms, these failures often happen silently, leaving users confused and frustrated.
5. Lack of Parallel Upload Strategy
Uploading files one after another might seem efficient in small-scale scenarios, but it doesn’t work well when demand increases.
Sequential uploads:
Take longer to complete
Underutilize available resources
Slow down the overall experience
At scale, this leads to noticeable delays and poor performance. Systems that don’t support parallel uploads struggle to keep up with user expectations.
6. No Global Infrastructure
If your upload system is tied to a single region, users in other parts of the world will feel the impact immediately.
They experience:
Higher latency
Slower upload speeds
Increased chances of failure
As your user base grows globally, these issues become more pronounced. Without distributed infrastructure, your system simply can’t deliver consistent performance.
7. Missing File Validation and Processing Strategy
At scale, file uploads involve more than just storing data. You need to manage what’s being uploaded and how it’s handled.
This includes:
Validating file types
Enforcing size limits
Converting formats when needed
Extracting metadata
If these processes aren’t automated, your system becomes inconsistent and harder to maintain. Errors increase, edge cases pile up, and the overall reliability of your upload pipeline starts to decline.
What Happens When Upload Systems Fail
When a file upload system starts failing, the impact goes far beyond just a broken feature. It creates a ripple effect across users, business performance, and engineering teams, often all at once.
User Impact
From a user’s perspective, even a single failed upload feels frustrating. The experience quickly breaks down when uploads stall halfway or fail without clear explanations. Most users don’t understand what went wrong. They just see that it didn’t work.
They try again. And sometimes again.
But after a few failed attempts, patience runs out. Many users simply abandon the process altogether, especially if the task feels time-consuming or unreliable.
Business Impact
These small moments of frustration add up quickly at the business level. Failed uploads can directly impact conversions, especially in workflows like onboarding, content submission, or transactions that depend on file uploads.
Over time, this leads to:
Lower conversion rates
Interrupted or failed transactions
A noticeable increase in support requests
More importantly, it damages trust. If users feel like your platform isn’t reliable, they’re far less likely to come back.
Engineering Impact
Behind the scenes, failing upload systems put constant pressure on engineering teams. Instead of building new features, developers end up spending time debugging issues in production.
This often leads to:
Ongoing firefighting and reactive fixes
Rising infrastructure and maintenance costs
Increasing difficulty when trying to scale further
What starts as a small technical issue can quickly turn into a long-term operational burden if not addressed properly.
How to Build a Scalable File Upload API
Now let’s move from problems to solutions. Building a scalable file upload API isn’t about one single fix; it’s about combining the right strategies to handle real-world conditions reliably.
1. Implement Chunked Uploads
Instead of uploading an entire file in one go, break it into smaller pieces. Each chunk can be uploaded independently, which makes the process far more resilient.
If something fails, you don’t have to restart everything. Only the failed chunks need to be retried, allowing users to resume uploads without losing progress. This simple shift dramatically improves reliability, especially for large files and unstable networks.
Parallel chunk file uploading
2. Add Intelligent Retry Logic
Failures are inevitable, so your system should be designed to handle them gracefully.
A robust upload system includes:
Automatic retries when a chunk fails
Exponential backoff to avoid overwhelming the network
The ability to recover partially completed uploads
Instead of treating failures as exceptions, you treat them as expected events and that’s what makes the system resilient.
3. Use Direct-to-Cloud Uploads
Routing files through your backend might seem logical at first, but it doesn’t scale well. A better approach is to upload files directly from the user to cloud storage.
The flow becomes simple:
User → Cloud Storage
This approach reduces the load on your servers, speeds up uploads, and removes a major bottleneck from your architecture. It also allows your backend to focus on what it does best, instead of handling heavy file transfers.
4. Enable Parallel Uploading
Uploading files or chunks one by one is inefficient, especially when users are dealing with large files.
By allowing multiple chunks to upload simultaneously, you can significantly improve performance. This leads to faster upload times, better use of available bandwidth, and a smoother experience overall.
5. Provide Accurate Progress Feedback
From the user’s perspective, visibility is everything. If they don’t know what’s happening, even a working upload can feel broken.
That’s why it’s important to show:
Real-time progress indicators
Clear upload status updates
Meaningful error messages when something goes wrong
This not only reduces frustration but also builds trust in your system.
6. Optimize for Global Performance
If your users are spread across different regions, your upload system needs to support that.
Using globally distributed infrastructure, such as CDN-backed uploads, regional endpoints, and edge networks helps ensure that users get consistent performance no matter where they are. It reduces latency, speeds up uploads, and lowers the chances of failure.
A content delivery network (CDN)
7. Automate File Processing
At scale, manual handling of files isn’t practical. Your system should automatically manage everything that happens after upload.
This includes:
Compressing files
Converting formats
Validating file types and sizes
Optimizing content for delivery
Automation keeps your workflow consistent, reduces errors, and ensures your system can handle increasing demand without added complexity.
Why Building This Internally Gets Complicated
At first, file uploads seem simple.
Just a file input and an API endpoint.
But at scale, complexity grows quickly:
Chunk management
Retry systems
Distributed architecture
Storage integrations
Security requirements
What starts as a simple feature becomes a long-term engineering challenge.
How Managed Upload APIs Solve These Problems
Instead of building everything from scratch, many teams use managed solutions like Filestack.
These platforms are designed specifically to handle scale.
Key Capabilities
Built-in chunking and resumable uploads
Direct-to-cloud infrastructure
Global CDN delivery
Automated file processing
Security and validation features
This allows teams to focus on their product instead of infrastructure.
Example Implementation Approach
A typical implementation is straightforward:
Integrate the upload SDK into your frontend
Configure storage and security policies
Enable chunking and retry logic
Connect uploads directly to cloud storage
In most cases, you can go from setup to production-ready uploads in a fraction of the time it would take to build everything internally.
Conclusion
File upload APIs don’t fail because of small bugs.
They fail because they aren’t designed for real-world scale.
A truly scalable file upload API requires:
Chunked uploads
Retry mechanisms
Direct-to-cloud architecture
Building this from scratch is possible—but complex.
For most teams, the smarter approach is to remove failure points instead of adding complexity.
Because at the end of the day, the goal isn’t just to upload files.
It’s to make sure uploads work reliably—every single time.
The post Why Your File Upload API Fails at Scale (And How to Fix It) appeared first on The Crazy Programmer.