At the end of this blog post, you will know:
what problems do they solve?
what is an ETag and how is it calculated?
how do they relate to If-None-Match and If-Match headers?
what do 412 Precondition Failed and 304 Not Modified got do to with all of that?
Of course, this is more theoretical content, and you can expect some pragmatic examples with Spring Boot and Ktor soon
Video Content
As always, if you prefer a video content, then please check out my latest YouTube video:
If you find this content useful, please leave a subscription
What Problems ETags Solve?
Let’s start everything by figuring out the most important thing- what actual problems Etags help us solve? At the end of the day, what is the point of any additional work if it does not bring any value?
Well, long story short, the Entity Tags help us to deal with two problems:
waste of bandwidth and resources to consume the response of unchanged data,
updating data that changed since we last fetched them.
Problem #1- Waste of Bandwidth & Resources
So what do we exactly mean by problem #1- the waste of bandwidth? Let’s imagine a pretty standard client <-> server communication. The client asks the server for some data, like product details (also known as entity, or resource in terms of REST). The server fetches necessary data from the database, sometimes performs additional actions, and eventually returns them to the client (let’s say a mobile application) with 200 OK status code.
Then, our client consumes that response- for example, converts the returned JSON and displays that to the user.
And up until now, everything is perfectly fine. But, let’s imagine a situation, in which our product remains untouched- no price, no title, nothing changes- but our client keeps querying the server. In such a case, the bandwidth used to transfer the exact same data over and over, and the client resources used to process that could be utilized better, right?
And as you might have guessed- that’s where ETags come with help
What is an ETag and How It is Calculated?
Long story short- ETag (aka Entity Tag)- uniquely identifies a version of the entity.
In other words, it is a bunch of characters (like 0633010ca130d326f83ef9fee25491e7e) that remain constant for a particular version of an entity. If the entity (product in our example) is updated, a new tag is generated and remains constant until the next update.
From the implementational perspective, this can be anything from a version field in the database, a hashed timestamp of an update, or a hash of the response. Oftentimes, this hash is obtained using the MD5 algorithm.
Solve Problem #1 With ETags
Alright, so how we can use this identifier/tag to fix the waste in our client <-> server scenario? Well, pretty easily.
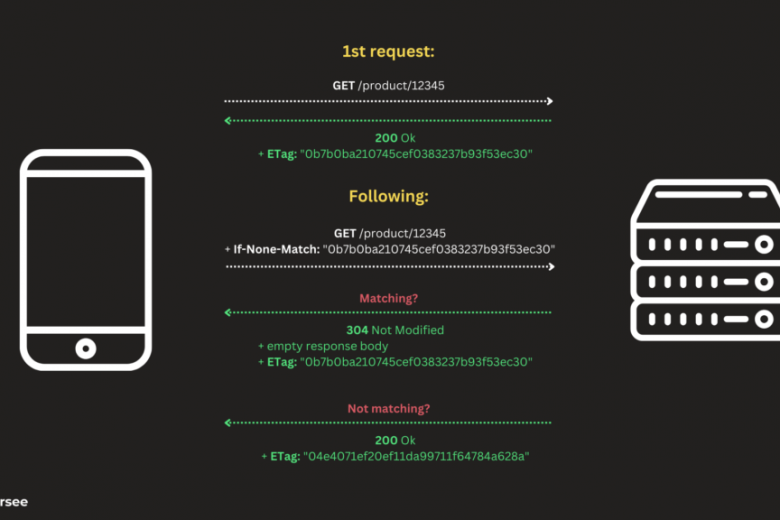
From the server perspective, whenever clients ask us for the data, we fetch them, calculate the ETag, and return 200 OK response with an additional ETag header. For example: ETag: «0e927523c29b6de3a9e3653df0e11762d» .
The client, on the other hand, is responsible for persisting ETags locally and later, sending them as an additional If-None-Match header, example: If-None-Match: «0e927523c29b6de3a9e3653df0e11762d» .
And whenever our server detects the If-None-Match , it fetches the data from the database, calculates the hash, and compares them. If they match, it means the resource has not changed since the last request. And in such a case, the server will send an empty response body with 304 Not Modified HTTP status code. If they don’t match, then the request body is sent along with 200 OK status code (and another ETag value).
As we can see, this allows us to fix the issue of wasted bandwidth, and potentially, the client resources. However, this does not prevent the client from making requests to the server, and the server from computing the data. For that purpose, we should lean towards client caching and proper cache control.
Problem #2- Update Changed Entity
At this point, we know both the issue and solution for repeated queries. So in this paragraph, let’s take a closer look into issue #2.
This time, let’s imagine we have 2 users that simultaneously fetched the same version of the entity- product in our case. Now, user 1 decides to update the product title. He hits update, his application sends a PUT request and the update succeeds. As we are using HTTP, user 2 (client) is not aware of the update. The application still displays old data. So, if he decides now to update some other field, like description, the PUT request may override the title with old data!
How ETags Can Help With Collisions?
In order to avoid this situation, we must make a small change in our API.
So, just like previously, when both clients make their 1st request, they get 200 OK response with an additional ETag header. For example: ETag: «0e927523c29b6de3a9e3653df0e11762d» .
Now, whenever any client application wants to update the product, it sends a PUT request with an additional If-Match header, like: If-Match: «0e927523c29b6de3a9e3653df0e11762d» . And this time, the server calculates the ETag of the desired entity before making any changes. If it does not match, it means that the entity was changed in the meantime, and the server notifies our client with 412 Precondition Failed status code.
Thanks to that, the client application has the chance to inform users about the updated entity/resource and handle that appropriately (for example, by displaying the popup).
This time, we can clearly see that the solution is not about performance and resources- it is about consistency.
Summary
And basically that is all for this article about ETags.
I hope it helped you to understand them better and provide you with ideas on how to apply them in your project.
Let me know your thoughts in the comments section!
The post What are HTTP ETags? appeared first on Codersee — Kotlin on the backend.