Hello and welcome to the first article in a series dedicated to integrating a Spring Boot Kotlin app with AWS S3 Object Storage, in which I will show you how to properly set up the connection and make use of the S3Client.
What can you expect today?
Well, at the end of this tutorial, you will know precisely how to connect to the S3 service, resolve the most common issues related to that, as well as how to perform basic operations on buckets and objects using the S3Client approach.
In the future content, we will work a bit with an asynchronous client, learn when to use S3Template instead, and learn how to write tests properly, so do not hesitate to subscribe to my newsletter
Project Setup
If you already have your Spring Boot project prepared, then feel free to skip this step.
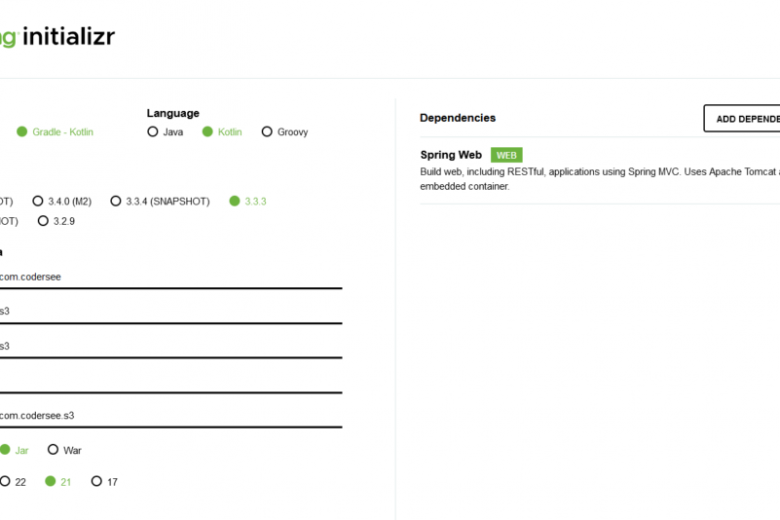
But if that is not the case, then let’s navigate together to the Spring Initializr page and select the following settings:
As we can see, nothing related to the AWS S3 yet, but we imported the Spring Web dependency so that we could expose REST endpoints to test.
As always, please generate the project, extract it on your local, and import it to your favorite IDE.
AWS S3 Dependencies
It is worth mentioning that the S3Client is not a Spring Boot concept, but a class that comes from the AWS SDK.
However, to make our lives easier when working with Spring, we can make use of the Spring Cloud AWS, which simplifies using AWS-managed services in a Spring and Spring Boot applications.
To do so, let’s navigate to the build.gradle.kts and add the following:
implementation(«io.awspring.cloud:spring-cloud-aws-starter-s3:3.1.1»)
Why do I pick it over the AWS Java SDK?
Because it auto-configures various S3 integration-related components out of the box. Additionally, we can quickly configure a bunch of things using the application.yaml. And lastly, we are all Spring boyzz here, we don’t do things manually
Create Test S3 Bucket
Following, let’s navigate to the AWS Console to prepare a test bucket.
Again, feel free to skip it if you are looking for Spring Boot details.
Then, let’s find the S3 (aka “Simple Storage Service”) in the search bar:
Nextly, let’s hit the Create Bucket , provide a name for it, and leave the rest as is:
If everything succeeded, then we should see our bucket on the list:
Excellent, at this point we can get back to our Spring Boot project :).
Test S3Client Connection
With all of that done, let’s figure out whether we can connect our local app with AWS using the S3Client.
To do so, let’s create the BucketController class and introduce the GET endpoint:
@RestController
@RequestMapping(«/buckets»)
class BucketController(
private val s3Client: S3Client
) {
@GetMapping
fun listBuckets(): List<String> {
val response = s3Client.listBuckets()
return response.buckets()
.mapIndexed { index, bucket ->
«Bucket #${index + 1}: ${bucket.name()}»
}
}
}
As we can see, the above logic will be responsible for exposing the GET /buckets endpoint and returning a list of bucket names as “Bucket #N: some-name”.
Moreover, the starter we are using automatically configures and registers an S3Client bean in the Spring Boot context. So, we simply inject that without any previous configuration.
Anyway, less talkie-talkie, and let’s test the endpoint:
curl —location —request GET ‘http://localhost:8080/test’
And depending on our local environment, we get the 200 OK with a bucket name:
[
«Bucket #1: your-awesome-name»
]
Or the error related to AwsCredentialsProviderChain:
software.amazon.awssdk.core.exception.SdkClientException: Unable to load credentials from any of the providers in the chain AwsCredentialsProviderChain(credentialsProviders=[SystemPropertyCredentialsProvider(), EnvironmentVariableCredentialsProvider(), WebIdentityTokenCredentialsProvider(), ProfileCredentialsProvider(profileName=default, profileFile=ProfileFile(sections=[])), ContainerCredentialsProvider(), InstanceProfileCredentialsProvider()]) : [SystemPropertyCredentialsProvider(): Unable to load credentials from system settings. Access key must be specified either via environment variable (AWS_ACCESS_KEY_ID) or system property (aws.accessKeyId)., EnvironmentVariableCredentialsProvider(): Unable to load credentials from system settings. Access key must be specified either via environment variable (AWS_ACCESS_KEY_ID) or system property (aws.accessKeyId)., WebIdentityTokenCredentialsProvider(): Either the environment variable AWS_WEB_IDENTITY_TOKEN_FILE or the javaproperty aws.webIdentityTokenFile must be set., ProfileCredentialsProvider(profileName=default, profileFile=ProfileFile(sections=[])): Profile file contained no credentials for profile ‘default’: ProfileFile(sections=[]), ContainerCredentialsProvider(): Cannot fetch credentials from container – neither AWS_CONTAINER_CREDENTIALS_FULL_URI or AWS_CONTAINER_CREDENTIALS_RELATIVE_URI environment variables are set., InstanceProfileCredentialsProvider(): Failed to load credentials from IMDS.]
Or even:
Caused by: org.springframework.beans.BeanInstantiationException: Failed to instantiate [software.amazon.awssdk.services.s3.S3ClientBuilder]: Factory method ‘s3ClientBuilder’ threw exception with message: Unable to load region from any of the providers in the chain software.amazon.awssdk.regions.providers.DefaultAwsRegionProviderChain@15f35bc3: [software.amazon.awssdk.regions.providers.SystemSettingsRegionProvider@2bfb583b: Unable to load region from system settings. Region must be specified either via environment variable (AWS_REGION) or system property (aws.region)., software.amazon.awssdk.regions.providers.AwsProfileRegionProvider@7301eebe: No region provided in profile: default, software.amazon.awssdk.regions.providers.InstanceProfileRegionProvider@76a805b7: Unable to contact EC2 metadata service.]
So, let’s learn why it worked (or not).
Configuring AWS Credentials
Long story short, the Spring Cloud AWS starter configures the DefaultCredentialsProvider that looks for credentials in the following order:
Java System Properties – aws.accessKeyId and aws.secretAccessKey
Environment Variables – AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY
Web Identity Token credentials from system properties or environment variables
Credential profiles file at the default location (~/.aws/ credentials) shared by all AWS SDKs and the AWS CLI
Credentials delivered through the Amazon EC2 container service if AWS_CONTAINER_CREDENTIALS_RELATIVE_URI environment variable is set and the security manager has permission to access the variable,
Instance profile credentials delivered through the Amazon EC2 metadata service
And if you got 200 OK, but you don’t remember specifying anything on your local machine, then I am pretty sure that the number 4 is the answer here
The .aws folder inside the home directory is a default location for credentials, and you could have populated that unconsciously, for example when configuring AWS CLI with aws configure. And the DefaultCredentialsProvider was smart enough to use it without your knowledge.
The autoconfiguration is a wonderful thing, but as we can see, it can backfire sometimes
On the other hand, if none of these 6 satisfies you, then Spring Cloud AWS allows us to use the access keys, too.
To do so, the only thing we need to do is add the following to the application.yaml:
spring:
cloud:
aws:
credentials:
access-key: your-access-key
secret-key: your-secret-key
Configure Region
OK, so at this point the problem related to the credentials should be gone. However, if we got the second error related to the region, then let’s see how it works internally, too.
Well, when we take a look at the DefaultAwsRegionProviderChain docs, we will see that it looks for the region in this order:
Check the aws.region system property for the region.
Check the AWS_REGION environment variable for the region.
Check the {user. home}/.aws/ credentials and {user. home}/.aws/config files for the region.
If running in EC2, check the EC2 metadata service for the region.
So, again, if we had the .aws credentials set, then this value came from there
And as you might already have guessed, yes, we can update that in the properties, too:
spring:
cloud:
aws:
s3:
region: us-east-1 #default is us-west-1
And at this point, when we rerun our application, then everything should be working, as expected.
AWS S3Client Operations
So, with all of that done, we can finally take a look at a few AWS S3Client capabilities. Of course, we will not cover all possible scenarios, so if you have a bit more specific use case, then I recommend checking the Spring Cloud AWS / AWS SDK documentation.
List All Buckets
Firstly, let’s get back to the listBuckets usage:
@GetMapping
fun listBuckets(): List<String> {
val response = s3Client.listBuckets()
return response.buckets()
.mapIndexed { index, bucket ->
«Bucket #${index + 1}: ${bucket.name()}»
}
}
Long story short, this function returns ListBucketsResponse that contains a list of all buckets owned by us. It is worth mentioning that we must have the s3:ListAllMyBucket permission.
Nevertheless, I wanted to emphasize one, important thing.
AWS SDK methods throw exceptions quite heavily. For example, the above may result in SdkException, S3Exception, or SdkClientException to be thrown. In a production-ready code, we must keep that in mind, handle them according to our needs and (if necessary) translate to appropriate HTTP status codes.
Create New S3 Bucket
Following, let’s expose a POST /buckets endpoint that will be used to create new buckets:
@PostMapping
fun createBucket(@RequestBody request: BucketRequest) {
val createBucketRequest = CreateBucketRequest.builder()
.bucket(request.bucketName)
.build()
s3Client.createBucket(createBucketRequest)
}
data class BucketRequest(val bucketName: String)
This time our function looks quite different- we must prepare the CreateBucketRequest that we pass to the createBucket function.
And that is quite a common thing when dealing with AWS S3Client in Spring Boot. The SDK methods expect us to provide different objects of classes extending the S3Request, like CreateBucketRequest, DeleteObjectRequest, etc.
What the createBucket does is pretty obvious, but we must be cautious about the bucket name, because the function may throw BucketAlreadyExistsException, or BucketAlreadyOwnedByYouException.
Of course, to test that, the only thing we need to do is to hit the endpoint:
curl —location —request POST ‘http://localhost:8080/buckets’
—header ‘Content-Type: application/json’
—data-raw ‘{
«bucketName»: «your-awesome-name»
}’
And if everything is fine, a new bucket should be created.
Create Object In The Bucket
So at this point, we know how to create buckets in AWS. Nevertheless, we use them to organise uploaded files.
And it is the right time to learn how we can upload a file:
// we must add the typealias to avoid name clash for the @RequestBody annotation 🙂
typealias PutObjectRequestBody = software.amazon.awssdk.core.sync.RequestBody
@RestController
@RequestMapping(«/buckets»)
class BucketController(
private val s3Client: S3Client
) {
@PostMapping(«/{bucketName}/objects»)
fun createObject(@PathVariable bucketName: String, @RequestBody request: ObjectRequest) {
val createObjectRequest = PutObjectRequest.builder()
.bucket(bucketName)
.key(request.objectName)
.build()
val fileContent = PutObjectRequestBody.fromString(request.content)
s3Client.putObject(createObjectRequest, fileContent)
}
data class ObjectRequest(val objectName: String, val content: String)
}
As we can see, this time, we make use of the putObject and the PutObjectRequest (you see the pattern now ).
Moreover, when preparing the request we must specify both the bucket name and our object key.
curl —location —request POST ‘http://localhost:8080/buckets/your-awesome-name/objects’
—header ‘Content-Type: application/json’
—data-raw ‘{
«objectName»: «file-example.txt»,
«content»: «My file content»
}’
As a result, a new text file named “file-example” with “My file content” in it should be created in the “your-awesome-name” bucket.
Of course, this is not the only method of S3Client that allows us to upload files, and sometimes the multipart upload might be a better choice for our use case.
List Objects From The Bucket
Nextly, let’s take a look what is the content of our bucket:
@GetMapping(«/{bucketName}/objects»)
fun listObjects(@PathVariable bucketName: String): List<String> {
val listObjectsRequest = ListObjectsRequest.builder()
.bucket(bucketName)
.build()
val response = s3Client.listObjects(listObjectsRequest)
return response.contents()
.map { s3Object -> s3Object.key() }
}
Similarly, we build the ListObjectsRequest instance, we perform the request using the listObjects and return an array with item names.
And this time, when we check with the following query:
curl —location —request GET ‘http://localhost:8080/buckets/your-awesome-name/objects’
We should get the 200 OK with the array:
[
«file-example.txt»
]
Fetch The Object From S3 Bucket
And although listing objects might be sometimes useful, I am pretty sure you would be more often interested in getting the actual object with a key:
@GetMapping(«/{bucketName}/objects/{objectName}»)
fun getObject(@PathVariable bucketName: String, @PathVariable objectName: String): String {
val getObjectRequest = GetObjectRequest.builder()
.bucket(bucketName)
.key(objectName)
.build()
val response = s3Client.getObjectAsBytes(getObjectRequest)
return response.asString(UTF_8)
}
Just like in the previous examples, we prepare the request with bucket name and object key, invoke the getObjectAsBytes and this time we print out the content to the output:
curl —location —request GET ‘http://localhost:8080/buckets/your-awesome-name/objects/file-example.txt’
# Response:
«My file content»
Of course, a friendly reminder that the AWS SDK throws the exceptions, and if the file does not exist, we will get the NoSuchKeyException.
Delete S3 Bucket
As the last step, let’s take a look at the logic necessary to delete a bucket:
@DeleteMapping(«/{bucketName}»)
fun deleteBucket(@PathVariable bucketName: String) {
val listObjectsRequest = ListObjectsRequest.builder()
.bucket(bucketName)
.build()
val listObjectsResponse = s3Client.listObjects(listObjectsRequest)
val allObjectsIdentifiers = listObjectsResponse.contents()
.map { s3Object ->
ObjectIdentifier.builder()
.key(s3Object.key())
.build()
}
val del = Delete.builder()
.objects(allObjectsIdentifiers)
.build()
val deleteObjectsRequest = DeleteObjectsRequest.builder()
.bucket(bucketName)
.delete(del)
.build()
s3Client.deleteObjects(deleteObjectsRequest)
val deleteBucketRequest = DeleteBucketRequest.builder()
.bucket(bucketName)
.build()
s3Client.deleteBucket(deleteBucketRequest)
}
As we can see, this time, we must perform our actions in a few steps.
Why?
The reason is simple:
Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Request processing failed: software.amazon.awssdk.services.s3.model.S3Exception: The bucket you tried to delete is not empty (Service: S3, Status Code: 409…
As we can see, the message above is pretty descriptive. Simply said- we cannot delete a bucket that is not empty.
So, our function utilizes the listObjects, so that we can get keys to delete, the deleteObjects to actually delete them, and deleteBucket to get rid of the bucket.
Summary
And that’s all for this first tutorial on how to integrate your Spring Boot application with AWS and make use of the S3Client to work with AWS S3. In the upcoming articles in the series, we will expand our knowledge to work with S3 even more efficiently.
I hope you enjoyed it and see you next time
For the source code, as always, please refer to this GitHub repository.
The post Spring Boot with AWS S3, S3Client and Kotlin appeared first on Codersee | Kotlin, Ktor, Spring.